Run your own "ChatGPT" like locally

Ollama is a tool that enables users to run advanced language models, such as Mistral or llama, - both ChatGPT competitors - on their local machines.
Unlike traditional AI solutions that rely heavily on cloud-based infrastructure, Ollama empowers users to harness AI capabilities locally.
This does not only reduces dependency on internet connectivity but also enhances data privacy and security.
Installing Ollama
The tool is available on MacOS, Linux and Windows in preview. Download and run the installer ⬇️ :

Choosing a model
Multiples models are offered for free on Ollama's website, letting you choose the one which best match your needs:
As a starter pack, I suggest to use Mistral (🇫🇷) or llama3.1 from Meta, two general purposes models :
Using a model locally
The first thing to do is start Ollama. Open the application and run the following command in your terminal to download llama3.1:
jeremy@macbookpro ~ » ollama pull llama3.1:8b
pulling manifest
pulling 87048bcd5521... 100% 4.7 GB
pulling 11ce4ee3e170... 100% 1.7 KB
pulling f1cd752815fc... 100% 12 KB
pulling 56bb8bd477a5... 100% 96 B
pulling e711233e7343... 100% 485 B
verifying sha256 digest
writing manifest
removing any unused layers
success You can interact with the model:
jeremy@macbookpro ~ » ollama run llama3.1:8b
>>> Send a message (/? for help)Using a WebUI to interact with Ollama models
As Ollama is design to be a cli tool, this is not really user friendly. However, it also comes with a WebUI:
 open-webui
open-webuiI recommend using Docker for running the WebUI, while keeping Ollama outside of Docker to optimize performance. Here's a docker-compose stack you can use:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- open-webui:/app/backend/data
ports:
- 3000:8080
environment:
- 'OLLAMA_BASE_URL=http://host.docker.internal:11434'
- 'WEBUI_SECRET_KEY='
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
volumes:
open-webui: {}
Here's the WebUI home after login:
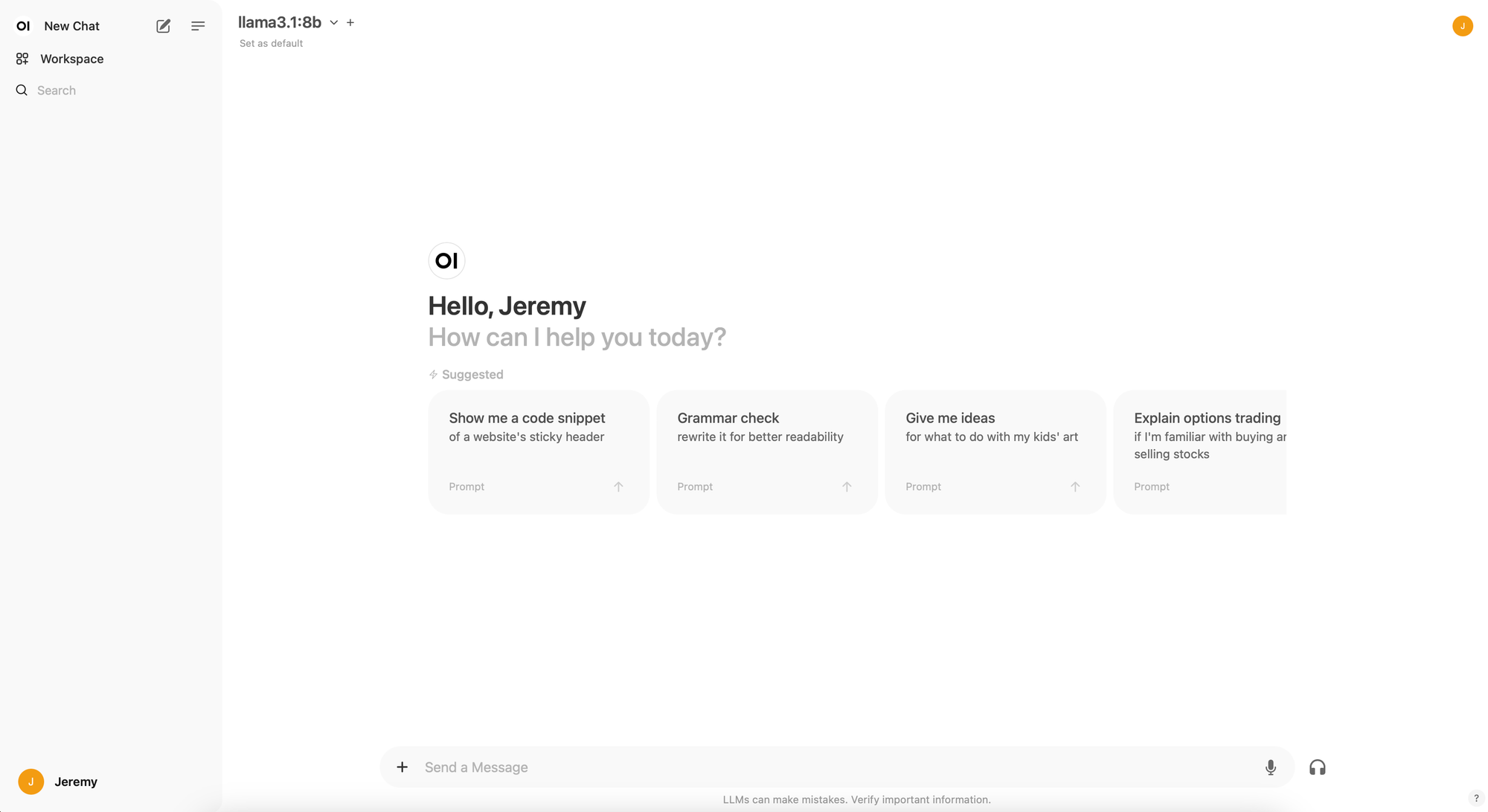
As you can see, llama3.1 is defined as default model for me, on top of the screen. Use the dropdown menu to select a model available on your computer, or download one. If no model is present, please check the following configuration:
Open the settings ⬇️
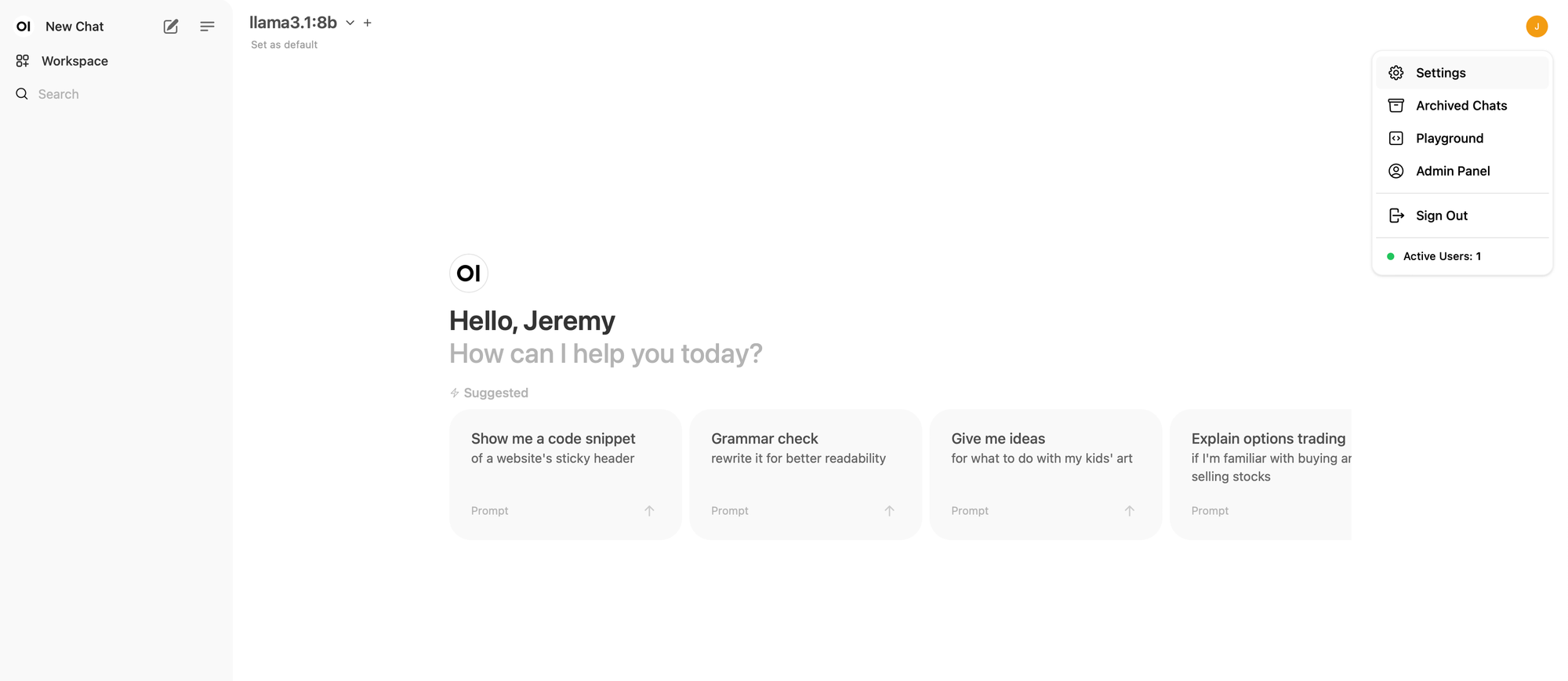
Then the admin settings ⬇️
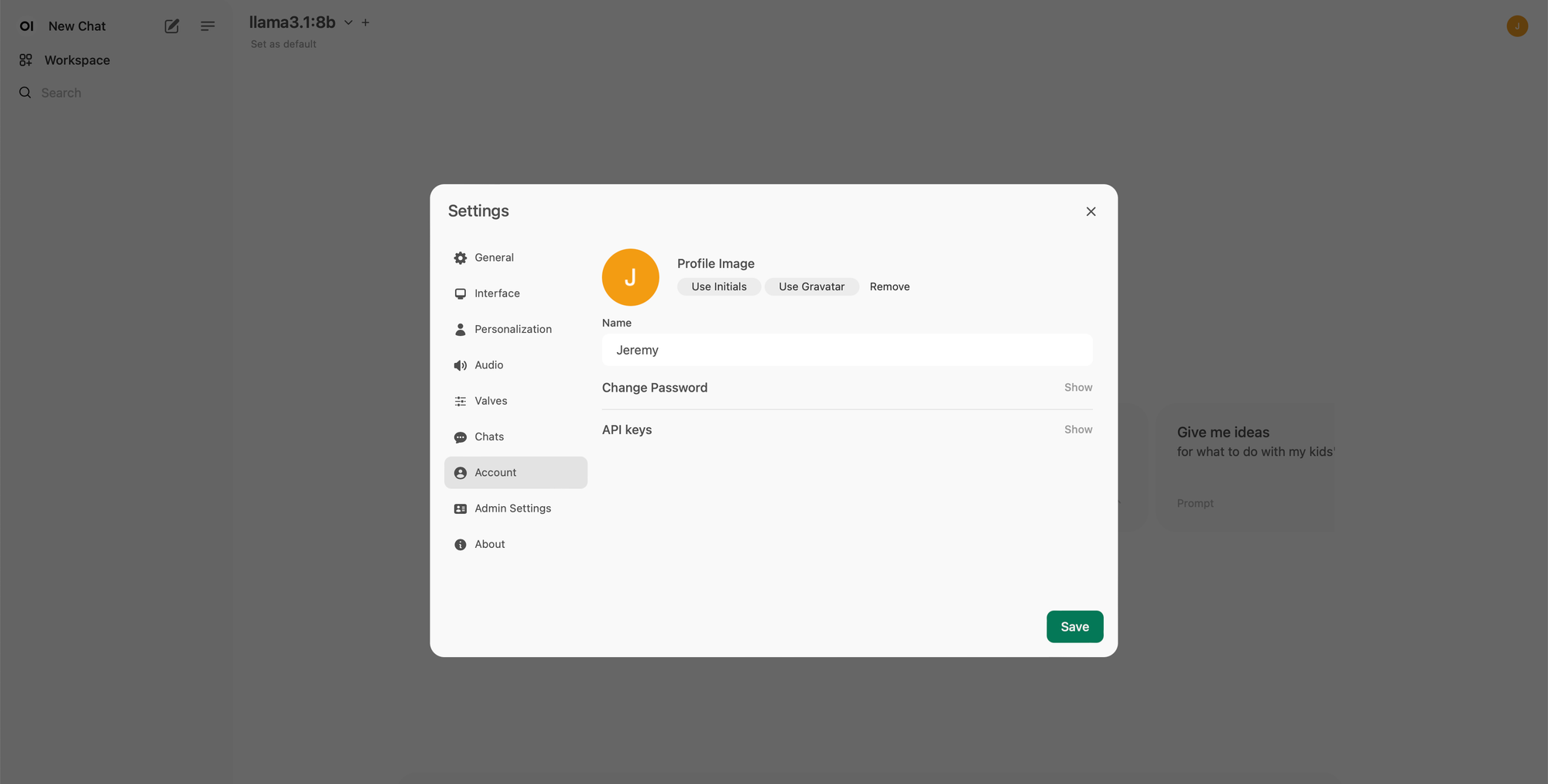
And then the connection panel ⬇️
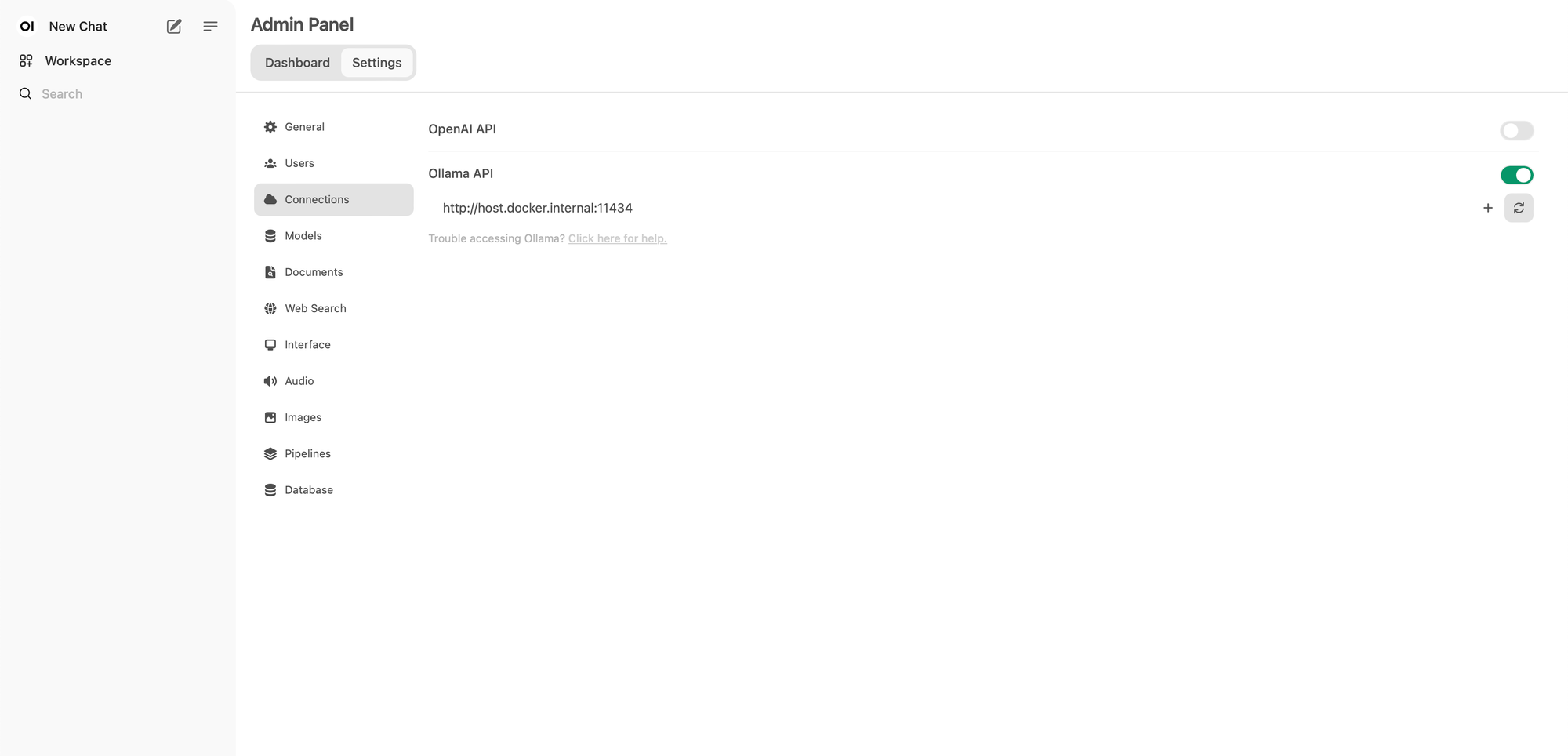
On this panel, make sure Ollama API URL match "http://host.docker.internal:11434"
Configure web browsing
Still in the admin panel, you can configure the web browsing capabilities of the models:
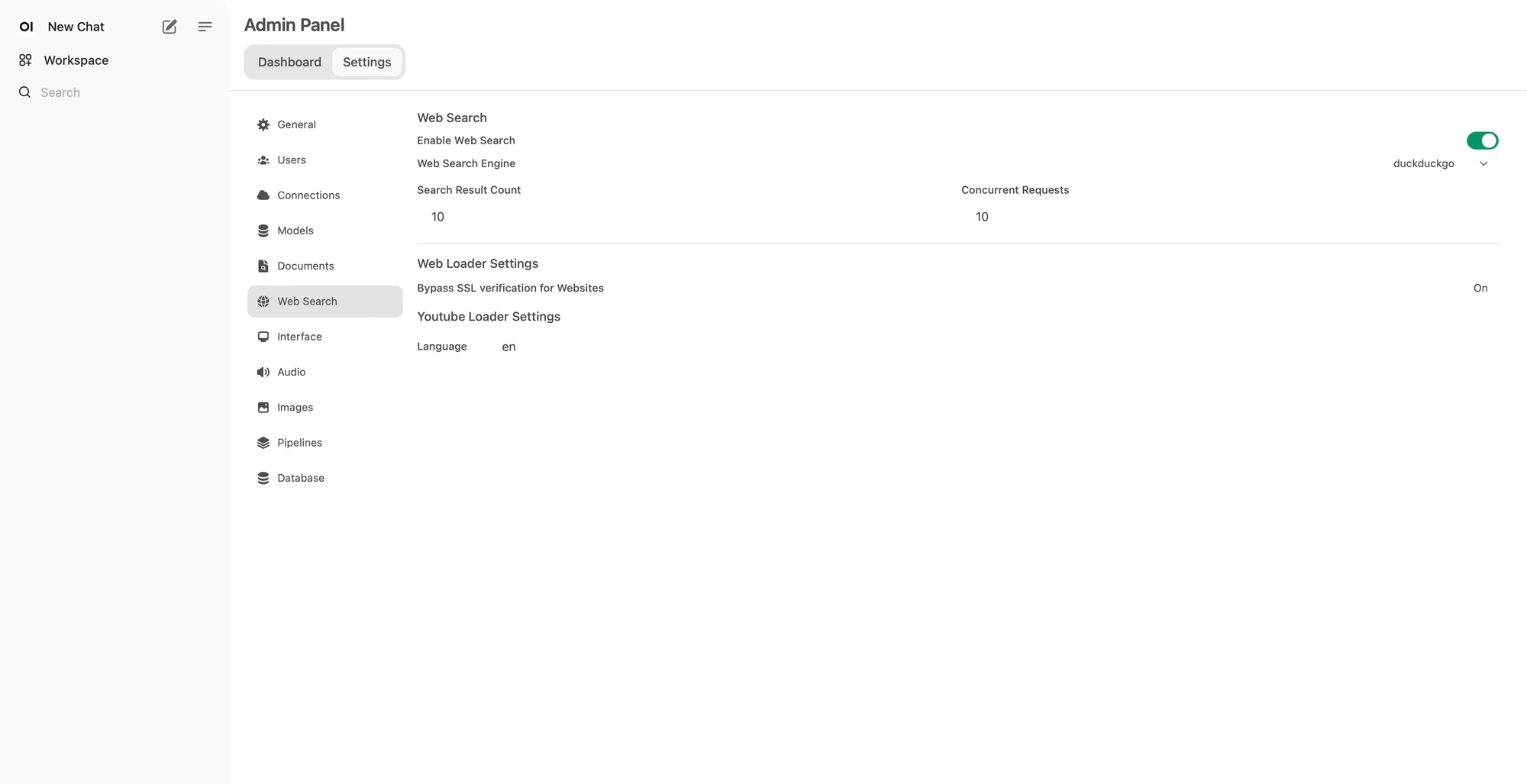
Performances
I'm running Ollama on a 2021 Macbook Pro M1 Pro 16 Gb of memory, and the requests are usually processed in 2-5 seconds, based on my experience with daily usage over several weeks.